
Table partitioning in Rails, part 1 - Postgres Stories

Table partitioning is not commonly used in Rails applications. The primary reason being, not many Rails applications grow to the extent that partitioning becomes necessary. For thousands or millions of rows, there are alternative solutions. These include indexing, vacuuming, configuration tuning such as work_mem, query rewriting and optimization, reducing selected columns, or caching. Even in smaller projects, it is possible to eventually reach a threshold for specific tables, leading us to partition those. A good example could be collecting GPS positions of any moving object, such as a driver. Even with hundreds or thousands of users, which is a relatively small amount, we could accumulate hundreds of millions or even billions of rows. It might be worthwhile to consider partitioning at this point. This could potentially help prevent performance issues associated with querying such a large tables.
In this part, I want to shortly explain, what partitioning actually is and how you can implement this mechanism for newly created table as partitioned table in Rails application. In the second part, I'll demonstrate an approach to migrate an existing table. So, let’s dive into the topic.
How it works
Scaling mechanisms in relational database management systems (RDBMS) often involve either vertical or horizontal partitioning, with the latter being of greater significance in most cases. In this article I want to focus on horizontal partitioning. Vertical partitioning is a comprehensible topic from the perspective of RDBMS. It involves splitting columns of a table into more refined, 'narrower' tables and each of this table has different structure. From Rails perspective, it would be breaking model into multiple smaller models, somehow associated with each other. On the other hand, horizontal partitioning relies on specific values in a chosen column. This may not be an obvious solution for a relational database. If done poorly, it can lead to much bigger problems with performance than those encountered before such partitioning.
Vertical partitioning
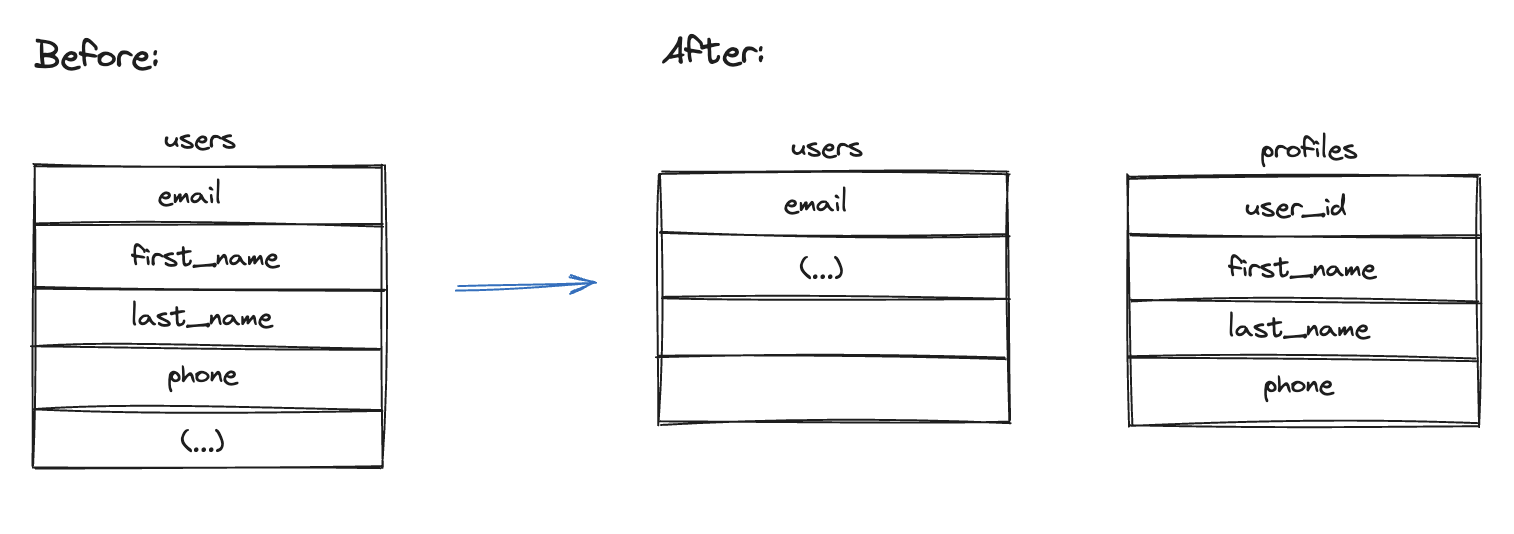
Vertical partitioning may be described in very short example, as it is only about moving columns from one table to another. If you have a users table that includes fields such as firstname, lastname, and phone_number, you can create a new table called profiles and move these columns to it. This leaves the User model solely with authentication details (like email and password), essentially achieving vertical partitioning. Performance-wise, this approach can be beneficial. It counters the typical ActiveRecord behavior of selecting all columns when using the model layer, which in turn reduces the time of execution of queries and memory usage. However, it's worth remembering that using select properly can help you with this problem without using vertical partitioning.
Horizontal partitioning
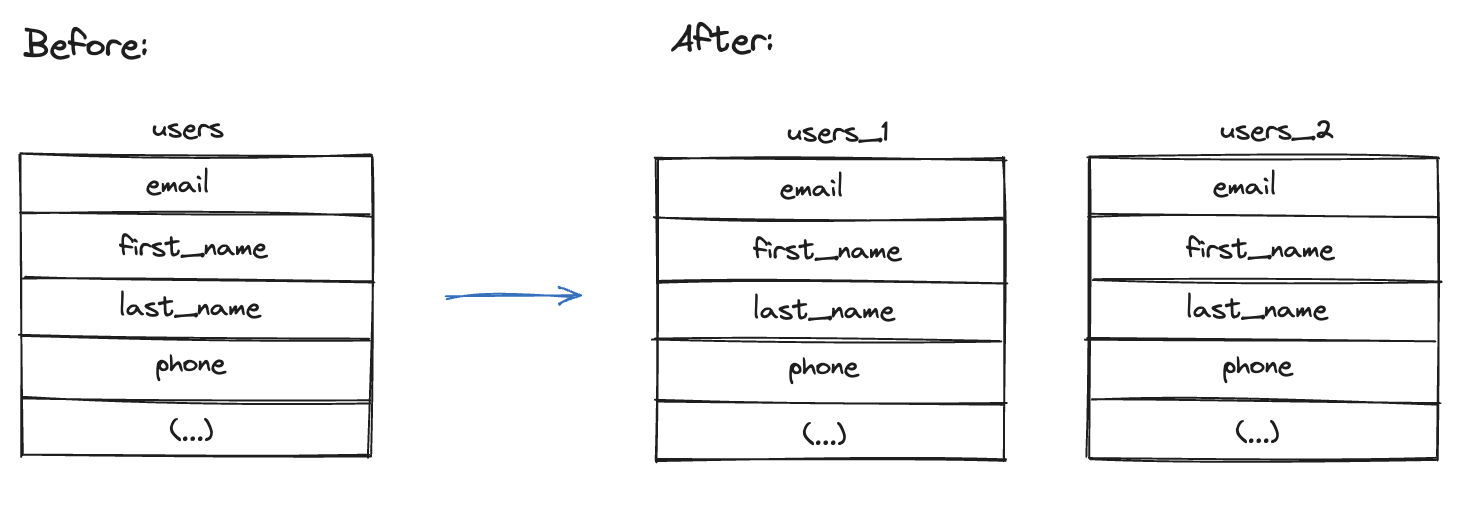
Things become interesting when discussing horizontal partitioning. This type of partitioning essentially breaks a table into several smaller tables. Each table maintains the same structure but is divided based on the value of a specific column (or columns). From the Rails perspective, the model structure remains the same - everything about horizontal partitioning occurs within the database itself.
When considering how to partition a table, PostgreSQL provides three options:
- Range partitioning: Divides data into ranges, often based on timestamps.
- List partitioning: Segments data based on specific discrete values, such as foreign keys.
- Hash partitioning: Distributes data based on hash values, specifying a modulus and remainder.
Each type serves a distinct purpose in partitioning tables. For a deeper understanding of these partitioning types and how to use them efficiently, refer to my piece on partitioning types in PostgreSQL.
The primary objective of such operation is about to increase query performance - it is especially efficient when range of query is contained in one or small amount of partitions. Beside, there are also some other pros - archiving, purging, and backup/restore are operations more straightforward, some bulk loads or deletions may be done by adding or dropping partitions - dropping partition is faster then bulk operation.
However, it's critical to note that introducing horizontal partitioning adds complexity to database design. Improper partitioning without well-thought-out ranges and/or partitioning values can result in reduced query performance. This performance degradation can be driven by the need to query multiple tables and the creation of overly complex query plans.
Partitioning in Rails application
As I mentioned before, one of the goals of this article is to present how to proceed with horizontal partitioning in your Rails application. Obviously, you can handle everything directly through SQL commands within psql client. However, from a maintenance perspective, this might not be the most convenient method. So, the first step would be to choose a proper tool.
The most popular tool for partitioning in PostgreSQL is pg_partman, an extension for our database server. Another tool worth mentioning is pgslice, a CLI tool written in Ruby. This may be a little bit closer to Ruby on Rails developers hearts, but it is not exactly what I was looking for.
I'd like to adhere somewhat to the Rails convention, so I'll be exploring a gem called pg_party. I understand that when making the decision to use partitioning, staying within the Rails environment is not the top priority, and you may need to familiarize yourself with the PostgreSQL environment anyway. But lets give it a shot and take a closer look.
Gem pg_party provides migrations and model helpers for creating and managing partitions in PostgreSQL with Declarative Partitioning, so at least version 10+. One of the problematic issues is that it doesn’t support schema.rb format, so we would be forced to move to sql format with structure.sql file.
For purpose of this article, I will show how to implement range partitioning - it is actually the most popular way of partitioning, as it serves well not only for querying data, but also for archiving it.
As a first task, lets try to create some brand new range partitioned table with some indexes and cron job for creating future partitions.
class CreateUsersTable < ActiveRecord::Migration[7.1]
def up
create_range_partition :users, partition_key: :created_at, template: false do |t|
t.string :email, null: false
t.string :first_name
t.string :last_name
t.string :username, null: false
t.integer :status, default: 0
t.jsonb :settings, default: {}
t.timestamps
end
end
def down
drop_table :users
end
end
In this common scenario, a partitioned users table is created with created_at as the partition key. The template option is set to false. This serves as a backup table to propagate indexes and constraints across partitions in PostgreSQL 10, since it lacks native support for these features on partitioned tables. In PostgreSQL 11, this is not a concern.
Next ones are partitions - I will create couple of them for nearest future - I assume beginning date as 01-01-2024 for table creation and split partitions by months:
class CreateUsersPartitions < ActiveRecord::Migration[7.1]
def up
create_range_partition_of(:users, name: :users_2024_01_01,
start_range: "2024-01-01", end_range: "2024-02-01")
create_range_partition_of(:users, name: :users_2024_02_01,
start_range: "2024-02-01", end_range: "2024-03-01")
create_range_partition_of(:users, name: :users_2024_03_01,
start_range: "2024-03-01", end_range: "2024-04-01")
create_default_partition_of(:users)
end
def down
end
end
I've created three partitions with specified ranges, as well as a default partition just in case. A cron job will be set up to handle the creation of partitions for future periods. Additionally, I left the down method empty in this case. I perceive the steps of creating a partitioned table and partitions as one. I separated them only for the article's purpose. If you want to remove single partition, the best would be to use detach_partition method and then drop specific table.
Last migration creates indexes - I will add index on username field:
class CreateUsersPartitionsIndexes < ActiveRecord::Migration[7.1]
def up
add_index :users, :username
end
def down
remove_index :users, :username
end
end
When creating a new table, I used the default method for creating an index on a partitioned table. This method doesn't support concurrency, but it does automatically propagate indexes over partitions. If there's a need to create indexes concurrently, the add_index_on_all_partitions method can be used, which concurrently propagates indexes over each partition. More about how to work with indexes in partitioned tables you can check in another part of this series.
One last step is to create scheduled job - this is User model configured for partitioned table:
class User < ApplicationRecord
range_partition_by :created_at
def self.create_next_partition
return if ActiveRecord::Base.connection.table_exists?(partition_name)
self.create_partition(
name: partition_name,
start_range: start_date.to_s,
end_range: end_date.to_s
)
end
def self.partition_name
"users_#{start_date.to_s}"
end
def self.start_date
Date.today.next_month.beginning_of_month
end
def self.end_date
Date.today.next_month.end_of_month
end
end
Main method here is create_next_partition which is responsible for creating partition for the next month. At the beginning it checks if specific partition already exists (for example, if it was already created in the migration) and then, creates new one if it is missing. Any existing indexes will be added to partition, as index is defined on parent table. The rest defines dates and name of partitions.
Now, the only thing left is to schedule a job. If there is no existing solution for scheduling in a project, whenever gem is an accurate solution for cron jobs.
Skipping all the configuration of scheduling gem - just add new job for schedule.rb file:
every :month do
runner "User.create_next_partition"
end
This is the last step - our job will check monthly to see if a partition for the next month has been created.
Final words
Summarizing what things were done in order:
- Create parent table
- Create couple of partitions for nearest future
- Apply indexes
- Implement method for creating new partitions based on date ranges
- Create cron job for new partitions
And that's it. We've covered everything necessary to create a new partitioned table in a Rails application. Remember, this particular approach is designed for date-range-based partitions. Different types of partitioning or ranges may require different methods. For instance, using values other than dates wouldn't require creating a cron job, but you would need to find a way to manage all existing and incoming values. Anyway, that could be a topic for another discussion.
In the next chapter, I will explain how to migrate existing common tables into partitioned ones, which is not as straightforward process as creating partitioned table from scratch.
Articles in this series
- Table partitioning in Rails, part 1
- Table partitioning in Rails, part 2
- Table partitioning types
- Indexing partitioned table