
Large Language Models (LLMs) understand human language extremely well. It almost feels like intelligence or magic. However, it's neither. It's a unique algorithm and a set of tools. This article describes one of its core mechanisms and shows how to leverage it using Ruby.
How LLMs understand human language
LLMs assign meaning to data (for example, a word or a sentence), by forming it as a vector of floating-point numbers.
"A dog is eating a shoe" could be expressed as [-0.04376212, -0.030682785, 0.001150967, -0.0004497381, 0.014188614, ...] Each number in this vector expresses a dimension of the given sentence. They enclose the information about the words included in the phrase and their connotations:
- dog: it's an animal, probably has a home, may be a puppy (they eat shoes) or just badly behaved
- shoe: the scene may be happening in a house, which is the place where it can be found
- eating: shows that the sentence describes an ongoing situation (as it's described using Present Continuous)
- The English language is used, which gives a background of similar situations described in English literature
All that (and much more) may be enclosed in the vector. The more dimensions we use, the richer the description becomes.
Embedding
Such a vector of floating-point numbers represents the semantic meaning of data and is called an Embedding. The number of dimensions limits the potential depth of the meaning captured in the embedding. At the moment of writing this article, these are some of the models and the number of their generated dimensions:
- BERT Base: 768
- BERT Large: 1,024
- ELMo: 512
- OpenAI's CLIP (ViT-B/32): 512
- OpenAI's CLIP (ViT-L/14): 768
- Gecko: 256 or 768
- OpenAI's text-embedding-ada-002: 1,536
- OpenAI's text-embedding-3-small: 1,536
- OpenAI's text-embedding-3-large: 3,072
An embedding may be also calculated using a mathematical algorithm (without using Artificial Intelligence). It would then be based purely on the shape of words, letters and punctuation. This way though, it would describe the shape of the sentence, not its meaning.
Get an embedding from LLM using Ruby
Most of the well-known LLMs can be used to generate an embedding. The most popular solutions, like ChatGPT, BERT or Ollama have dedicated models for it, which provide much better results than the general-purpose ones. Check the documentation of your tools to select the most appropriate one for you.
Get an embedding from ChatGPT using API
ChatGPT offers several models which can be used for generating embeddings. Here is an example of using "text-embedding-3-large", which returns 3072 dimensions.
url = "https://api.openai.com/v1/embeddings"
api_key = OPENAI_API_KEY
payload = {
model: "text-embedding-3-large",
input: "Ruby is great for writing AI software"
}.to_json
response = RestClient.post(
url,
payload,
{
Authorization: "Bearer #{api_key}",
content_type: :json,
accept: :json
}
)
embedding = JSON.parse(response.body).dig("data", 0, "embedding")
embedding.count
# => 3072
embedding[0..5]
# => [-0.011368152,
# -0.0082968585,
# -0.016695607,
# 0.02040736,
# 0.031557173,
# 0.042532317]
Get an embedding from ChatGPT using openai gem
The same can be achieved using a well-known ruby-openai gem:
require "openai"
client = OpenAI::Client.new(access_token: OPENAI_API_KEY)
response = client.embeddings(
parameters: {
model: "text-embedding-3-large",
input: "Ruby is great for writing AI software"
}
)
embedding = response.dig("data", 0, "embedding")
Get an embedding from ChatGPT using langchainrb gem
You may also use Langchain, which is a complex tool for building LLM-powered applications in Ruby.
gem "langchainrb"
llm = Langchain::LLM::OpenAI.new(api_key: OPENAI_API_KEY)
response = llm.embed(
model: "text-embedding-3-large",
text: "Ruby is great for writing AI software"
)
embedding = response.embedding
Get an embedding from OLLAMA using API
An example of getting an embedding from a different model
ollama_url = "<http://127.0.0.1:11434/api/embeddings>"
payload = JSON.generate(
model: "mxbai-embed-large",
prompt: "Ruby is great for writing AI software"
)
response = RestClient.post(ollama_url, payload)
response_body = JSON.parse(response.body)
response_body.dig('embedding')
Compare embeddings
Embeddings coming from the same model may be compared for similarity (or distance) between each other. Various measures can be used for this purpose, including:
- Cosine Similarity
- Euclidean Distance
- Manhattan Distance (L1 Distance)
- and many others.
The result of a comparison depends on the chosen measure. Some, like Cosine Similarity, provide values between -1 and 1, where values closer to 1 indicate greater similarity. Others, like Euclidean Distance, range from 0 to infinity, with smaller values indicating greater similarity. For most applications, it might be necessary to normalize the values to a range of (0, 1) to make them well-comparable and useful.
Cosine similarity implementation in Ruby
Each of the measures is a mathematical formula, which can be implemented in Ruby. The formula for cosine similarity is
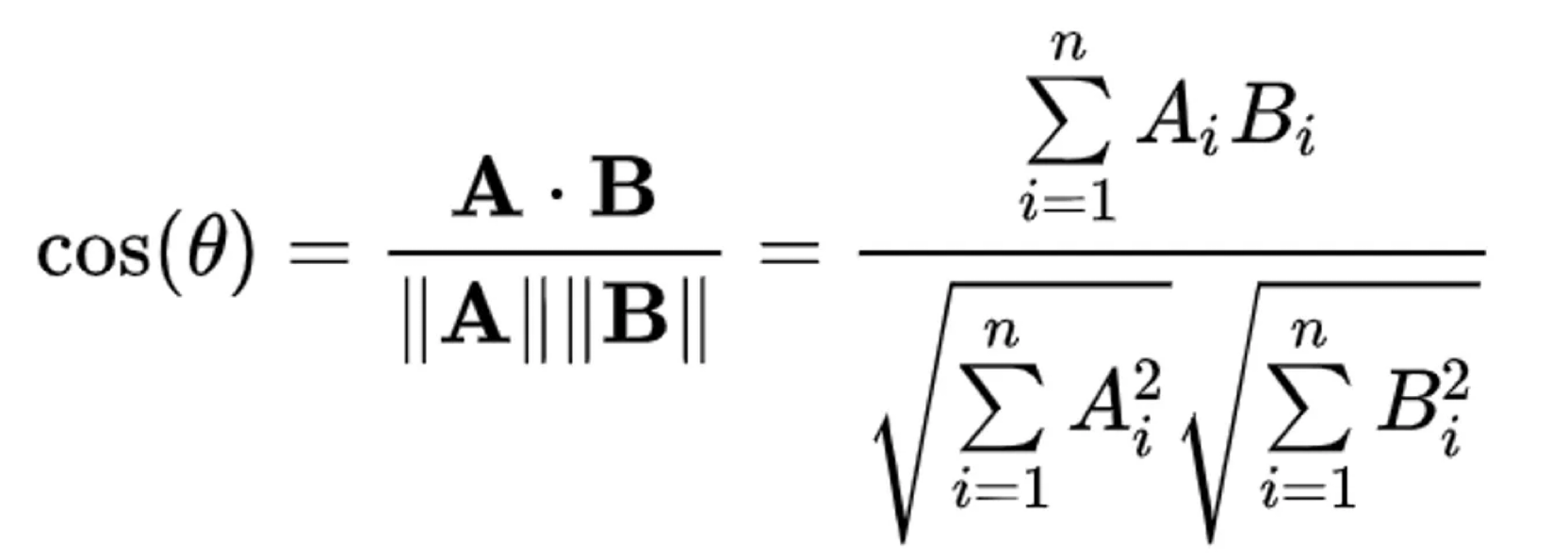
An implementation of the Cosine Similarity could look like:
def cosine_similarity(vect1, vect2)
dot_product = vect1.inner_product(vect2)
magnitude_product = Math.sqrt(
vect1.inner_product(vect1) * vect2.inner_product(vect2)
)
dot_product / magnitude_product
end
Compare embeddings in Ruby using Cosine Similarity
In order to compare two phrases, we need to:
- get embeddings of each from an LLM
- compare the embeddings, using a selected measure
openai = OpenAI::Client.new(access_token: OPENAI_API_KEY)
phrases = [
"Ruby is great for writing AI software",
"In Madrid, life’s best moments start with tapas and friends."
]
embeddings = phrases.map do |phrase|
get_embedding(openai, phrase)
end
similarity = cosine_similarity(*embeddings)
The result of such an operation is
puts "Cosine Similarity: #{similarity}"
=> Cosine Similarity: 0.07077303247793154
which shows that these phases have very little similarity.
When taking two sentences which describe a similar concept we get a much higher result:
phrases = [
"five plus ten is",
"thirty minus fifteen equals"
]
# ...
=> Cosine Similarity: 0.6360533632457297
But two phrases describing a near identical situation score even higher:
phrases = [
"She loves worldwide trips.",
"She enjoys traveling globally."
]
# ...
=> Cosine Similarity: 0.8161213344867835
Applications based on embeddings
Embeddings and their comparisons are powerful for tasks requiring similarity or categorization. Other use cases include enabling nuanced and efficient handling of text, images or user behavior. No matter if you need to provide semantic search, recommendations, categorization or fraud detection, embeddings may just be the correct tool for you.
Video presentation
- Paweł Strzałkowski, RAG and Vector Search in Ruby
Articles in this series
- LLM Embeddings in Ruby
- Vector Search in Ruby

Check my Twitter

Check my Linkedin

























